



Generative AI is revolutionizing multiple industries, and it is expected to continue driving significant transformations worldwide. The most common and widespread use has been free-form text generation in the style of chatbots such as ChatGPT and various similar applications. However, another area where it is already having a strong impact is software development. Creating LLM systems with embedded model calls inside an application’s or program’s code, or even chaining model outputs, is becoming a new standard for adding functionality. Therefore, knowing how to leverage the capabilities of these models and successfully integrate them becomes a tangible competitive advantage.
However, these models possess a characteristic that directly conflicts with the traditional programming paradigm: their output is non-deterministic, which is fundamentally at odds with conventional code. When we cannot know with certainty what format we will receive, it becomes difficult to chain tasks, invoke APIs, extract or persist information, or handle other functionalities programmatically.
Consider some use cases where obtaining a predictable response can be vital:
- Automatically evaluating customer or user reviews of my products according to specific categories, storing the classification in a database table, and generating a BI dashboard or alerts for products with high dissatisfaction.
- Extracting specific fields from legal or tax documents (dates, amounts, counterparties) without relying on the style in which the text was written.
- Evaluate responses from a customer service AI chatbot in terms of helpfulness, kindness, hallucination or other metric.
- Routing user query to a specialized agent based on the content of that query.
All these problems share the fact that they involve free-form text input that can be very difficult or impossible to manage with regular expressions or NLP techniques, and that they require a fixed output. The solution: structured outputs.
Structured outputs are a capability that leverages the function-calling feature offered by major LLM providers in some fine-tuned models, and which IBM watsonx exposes natively, to deliver responses in a predetermined JSON format. You can think of this capability as the developer writing a contract (a JSON schema) that the model reliably fulfills. In watsonx, models such as Granite 3.3 8B, Llama 4 Maverick and others support structured outputs thanks to function calling. This opens the door to countless applications, from simple information extraction or classification solutions to chained tasks where one model’s output becomes the next model’s input, like an agent pipeline, or feeds a conventional function within a code pipeline. The result is more maintainable code and often allows you to distribute the cognitive load of much more complex processes (divide and conquer).
Example
To better illustrate how practical this can be, let us examine a simple example in a Python notebook using:
- Granite 3.3 8B as the LLM in IBM watsonx.
- Langchain, a library that facilitates the use of language models.
- Pydantic to define and validate the structure we expect.
The process we want to automate is the extraction of information from invoices. We have the invoice content, but each invoice is different, with formats that vary greatly in how they present the information. Below is one example format among the many we might encounter:
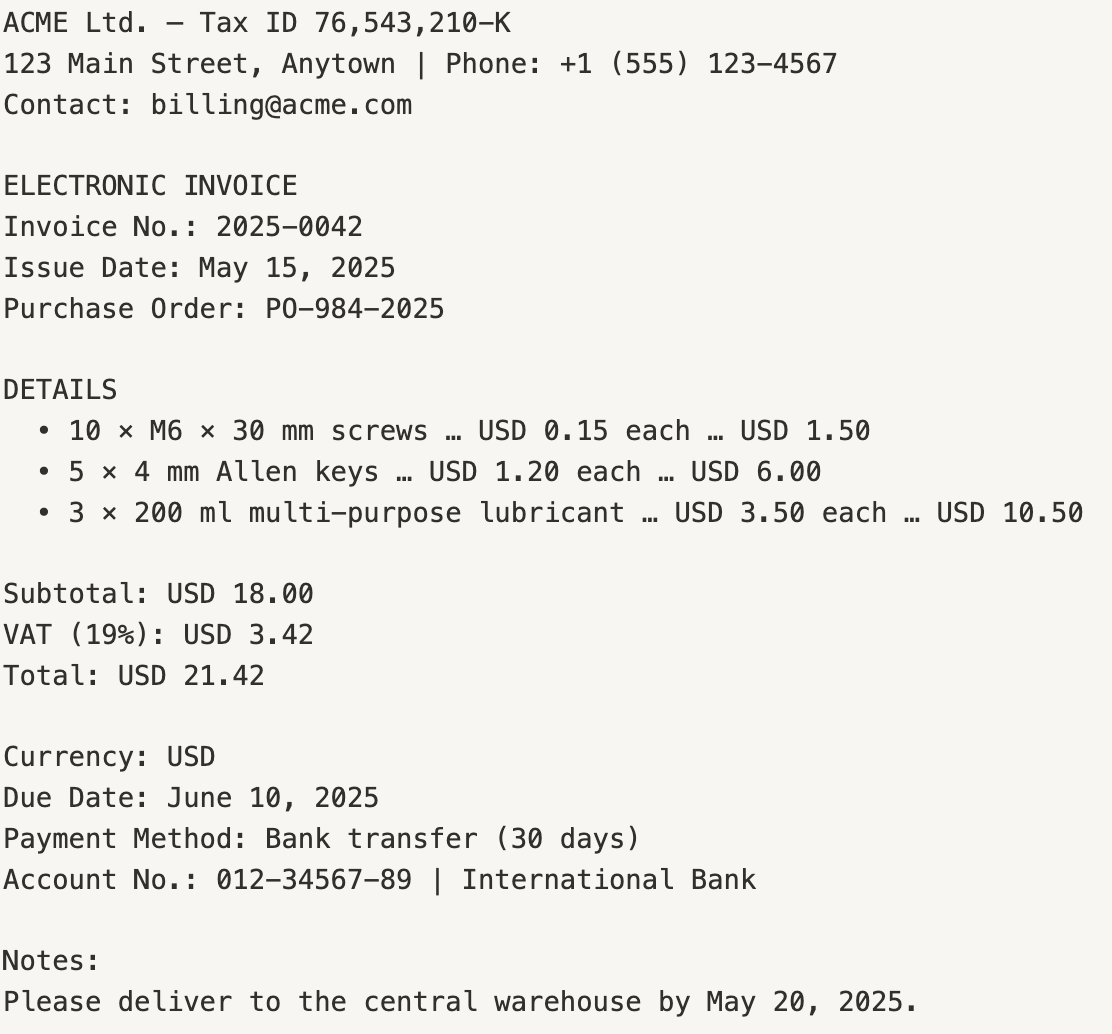 From this, we need to extract:
From this, we need to extract:
- Purchase order number
- Invoice date
- Subtotal amount
- Tax amount
- Total amount
- List of products (an indeterminate number of items, for which we need name, quantity, and unit price)
First, we will install the appropriate libraries and import them into our notebook where we will perform the exercise. We must have the necessary credentials to connect to watsonx.
 We can create a simple prompt that helps the model understand its role, the problem it must solve, and guides it through potential issues it may encounter. Below is an example in which we insert the invoice content:
We can create a simple prompt that helps the model understand its role, the problem it must solve, and guides it through potential issues it may encounter. Below is an example in which we insert the invoice content:
 Once we have a basic prompt, we need to generate the structure we will request from the LLM. For this, we will use Pydantic. In this case, we will define the schema for each individual product and the invoice schema, which will include a list of products.
Once we have a basic prompt, we need to generate the structure we will request from the LLM. For this, we will use Pydantic. In this case, we will define the schema for each individual product and the invoice schema, which will include a list of products.
 Then we instantiate our LLM by specifying the model ID we want to use, in this case Granite, and the project ID.
Then we instantiate our LLM by specifying the model ID we want to use, in this case Granite, and the project ID.
 Finally, using the .with_structured_output method, we provide the expected output schema and invoke the model with the prompt that includes the invoice information we are analyzing.
Finally, using the .with_structured_output method, we provide the expected output schema and invoke the model with the prompt that includes the invoice information we are analyzing.
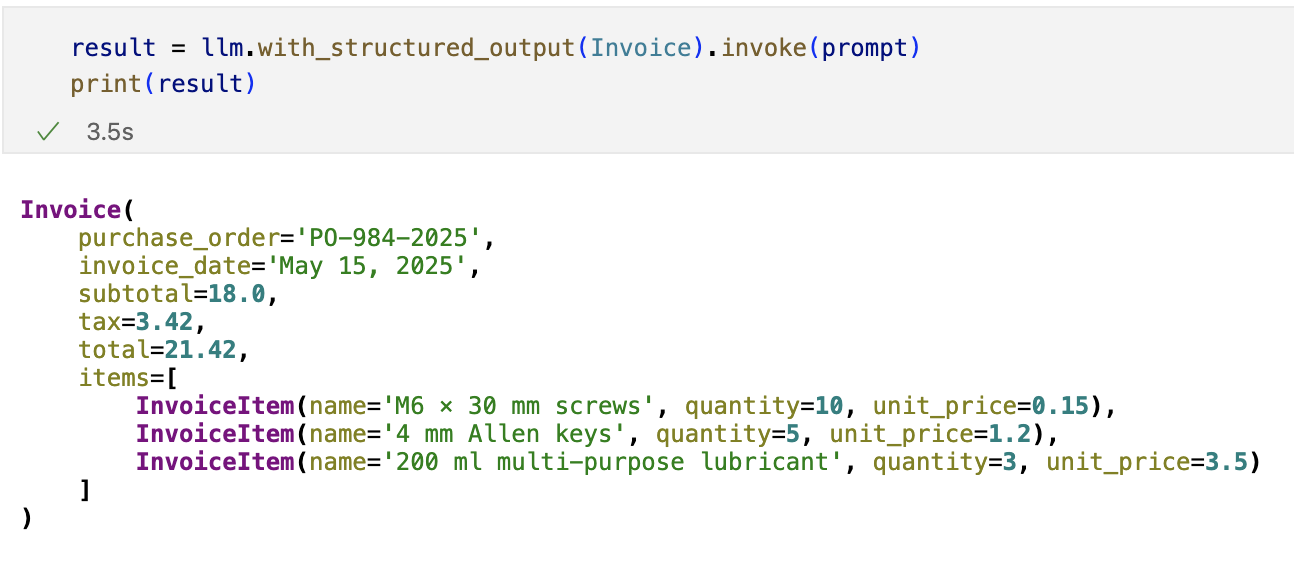 Upon obtaining the result, we can see that the model perfectly adhered to the requested format based on the data we provided and did so in a very short time. Furthermore, behind the scenes it validated the response against the schema, so we do not need to implement complex logic for this.
Upon obtaining the result, we can see that the model perfectly adhered to the requested format based on the data we provided and did so in a very short time. Furthermore, behind the scenes it validated the response against the schema, so we do not need to implement complex logic for this.
This is a very simple example; however, we can extend it much further. Perhaps we need the date in a specific format or want to provide instructions at the level of each schema field. Or maybe we want to use this model’s response to feed an internal system or another model with a task that requires the invoice data to be clean.
Link to sample code: https://github.com/matiasBarrera98/structured_outputs
Summary
The ability to generate structured outputs in IBM watsonx bridges the gap between the creativity of the models and the predictability demanded by traditional code. It delivers reliable responses that can be chained into subsequent tasks without complex validation, cleaning, or advanced NLP techniques, turning LLMs into components ready to integrate into any enterprise pipeline.
I encourage development teams and AI professionals to experiment with this functionality and take advantage of the wide range of possibilities it offers as an additional tool. With watsonx and structured outputs, software development and generative AI converge like never before, providing a competitive advantage worth exploring starting today.








